Nov 09, 2018 原创文章
Attentive Generative Adversarial Network for Raindrop Removal from A Single Image
论文下载地址:http://openaccess.thecvf.com/content_cvpr_2018/papers/Qian_Attentive_Generative_Adversarial_CVPR_2018_paper.pdf
论文摘要
相机镜头前的雨滴会妨碍背景场景的可视性并显着降低图像质量。
现实存在的问题:
1、被雨滴遮挡的区域并不会事先给出。
2、被雨滴遮挡的背景信息是完全丢失的。
算法的核心思想:
在生成和分类网络中加入 视觉注意力(visual attention)。
在训练过程中 视觉注意力(visual attention) 学习雨滴及其周边区域,通过将这些信息加入到网络中,生成网络(generative network )会在雨滴及其周边区域的结构上耗费更多的注意力,而判别网络(discriminative network)则可以用来评估雨滴去除后的区域与背景的一致性。
建立计算模型:

其中:I 为彩色输入图像,M为二进制掩码(掩码为1时表示这片区域被雨滴遮挡,为0时则表示这片区域为不含雨滴的背景),B为背景图像,R为雨滴所带来的影响(背景信息和环境反射的光线经过复杂的混合,透过粘附在镜头或挡风玻璃上的雨滴,在雨滴及其周边产生影响,但这同时也会携带一些背景信息)。⊙ 表示对应位置相乘(element-wise multiplication)。

网络设计

网络结构如上图所示
生成网络
生成网络包括两部分 attentive-recurrent network 和 contextual autoencoder。其中: attentive-recurrent network 用来发现输入图像需要提升注意力的区域。这些区域主要是被雨滴遮盖的部分及其周边的区域,这些区域需要 contextual autoencoder 的关注,以此恢复被雨滴遮盖的区域。同时判别网络会对这些区域进行进行重点评估。
注意力递归网络 Attentive-Recurrent Network
视觉注意力模型 (Visual attention models)常被用于确定图像中的目标区域并计算该区域的特征,并且在视觉识别和分类等场景得到了应用。在生成无雨滴背景图像的算法中,视觉注意力模型的作用在于使网络知道哪些区域应该被关注。
在该算法中,使用递归网络(recurrent network) 生成视觉注意力映射图(Visual attention map)。在递归网络中,每个block包含5层ResNet用于提取输入图像的特征和前一个block的mask,以及一个卷积LSTM单元和一个卷积层,用于生成二维的数视觉注意力映射图。
视觉注意力映射图

在该算法中,通过学习依次得到的映射图(如上图 Figure 3 所示 ),是一个0~1范围内的矩阵。从0到1依次表示没有雨滴的区域到有雨滴的区域,即使在包含雨滴的地方映射图的值也是不同的,因为雨滴及其周边区域的透明度不同,且不完全遮挡背景,从而传达一些背景信息。
LSTM (long short-term memory)单元
LSTM单元包含有:Input Gate $i_t$,Forget Gate $f_t$,Output Gate $o_t$,Cell State $C_t$。state 和 gate 之间的交互遵循时间顺序,如下式所示:
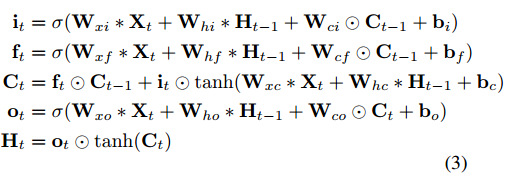
其中:$X_t$ 是ResNet生成的特征,$C_t$ 将LSTM的Cell State编码送入下一个LSTM,$H_t$ 表示LSTM单元的输出特征,操作符$*$表示卷积操作。
LSTM单元将输出送入一个卷积层,以此生成2D注意力映射图$A_t$。
在模型的训练初始化过程中,映射图初始化为0.5。在每一个时间步过程中,将当前产生的映射图与输入图像串联送入递归网络的下一个block。
Loss Function 损失函数

损失函数如上式所示。其中$A_t$表示注意力映射图,M为当前训练样本对差值的二进制掩码,损失函数为两者之间的均方差损失(MSE Loss)。整个计算过程共迭代N次,在这里N设置为4,θ设置为0.8,N越大效果越好,但也需要更大的内存空间。

随着迭代的进行,迭代网络可以更多的关注于 raindrop regions 和 relevant structures
上下文自动解码器 Contextual Autoencoder

上下文自动解码器用来生成去除雨滴的图像。其输入包括两部分,其一是原始的输入图像,其二是通过注意力递归网络所生成的注意力映射图。
在Figure 4中展示了自动解码器的网络结构。在网络中共包含16个 conv-relu block ,skip connection 用来避免输出模糊。
Loss Function 损失函数
在解码器网络中使用了多尺度损失函数(Multi-scale Losses)和感知损失(Perceptual Loss)。
1、多尺度损失函数
通过使用多尺度损失函数,解码器可以在不同的尺度上提取特征。以此得到不同尺度下的上下文信息(Contextual Information)
损失函数定义如下:

其中:$S_i$为解码层的第i个输出值,$T_i$为第i层的数值的真实值,$\left(λ_i\right)^M_{i=1}$ 为不同尺度的权重值,尺度越大权重越大。在具体的细节上,如Figue 4所示,采用输出的第一层、第三层和第五层,其大小分别为原始图像大小的1/4、1/2 和 1,其对应对应的权重值分别为0.6、0.8 和 1.0 。
2、感知损失
如Figure 4所示,感知损失用来测算 自动编码器输出的特征映射 和 无雨滴的干净图像(ground-truth clean image)的特征映射 的全局差异(global discrepancy)。
损失函数定义如下:

其中:VGG是预训练的CNN网络VGG-16,用来计算输入图像的特征映射。O是自动编码器的输出,$O = G(I)$,T是无雨滴的干净图像。
3、生成网络的损失值计算
综上,可得整个生成网络的损失函数为:

判别网络

判别网络的网络结构如Figure2所示。
在判别网络中共有7层卷积核为3×3的卷积层,一个大小为1024的全连接层,最后使用一个 sigmoid 激活函数,将输出映射到(0,1)区间内,值的大小表示判断为真的概率。
在去雨滴问题网络模型并不知道雨滴在图像中的哪个区域,因此判别网络需要自己去判断图像中的哪些区域被雨滴遮挡。在该算法中使用注意力判别(attentive discriminator)判断雨滴遮挡的区域,通过注意力递归网络(attentive-recurrent network.)生成注意力映射来实现注意力判别。
Loss Function 损失函数

其中:$L_{map}$ 是判别器内部网络层提取的特征和最终的注意力映射图之间的loss。$γ$的值设置为 0.05。其计算值如下:

其中:$D_{map}$表示判别网络内部网络层生成2D图像特征。$D_{map}(O)$为生成网络生成的雨滴去除后的图像在判别网络中提取到的2D图像特征,$D_{map}(R)$为训练数据集中没有雨滴的图像的在判别网络中提取到的2D图像特征。
上式的第一部分表示:$D_{map}(O)$ 与 $A_N$ (最终生成的注意力映射图) 计算 MSE Loss。第二部分表示:$D_{map}(R)$ 与 0 (全部值为0的注意力映射图,由注意力映射图的定义可知,全为0表示图像中不包含雨滴,不需要额外的注意。)计算MSE Loss。



相关文章:
初识VGG网络模型 # VGG, 卷积网络, 卷积层, 论文阅读 Dec 24, 2018 原创文章Hello Pytorch 叁 -- 简单理解生成对抗网络(GAN) # 深度学习, Pytorch, 生成对抗网络, GAN Oct 29, 2018 原创文章